
Neural networks are black boxes and how they create their results is a very complex task, as the field of sensitivity analysis is a developing field of research.
In this post, you will learn a method how to unpack the black box of neural networks a bit and see, which input values create which outcomes. For this, we will create a small dataframe, containing different input vectors with one output class, which makes it a classification task. Then the data will be sent into a simple dense-model. Afterwards we will analyze, how we can determine, which input influences the prediction of a class.
Into the python code!
First we import the necessary modules and create our test dataframe in pandas.
For converting our Y-labels to indices, which the model can use, we use numpys unique function, which returns us the class-indices of the labels, when we set the return_inverse parameter to true.
For our X-labels we need to do some preprocessing. As we want to inspect the influence of our values, we need to get rid off the positional information. Thats why we first use tf.keras.utils.to_categorical for converting our labels into categories of a defined shaped (thats why we cannot use np.unique() here again, also because we now have a list structure, not only strings anymore) .
Then we create our final train variables, and create the datastructure, the model needs.
Afterwards we create a simple model, which takes as input a vector of rank 1, containing 3 values. It passes the information into two dense layers until it outputs the class probabilities in the output layer with the softmax activation function.
As optimizer we use the well working adam, as loss the sparse categorical crossentropy, since our y-labels are not one-hot encoded but integers and we use the simple accuracy metric.
Then the model is trained by
Now when we reached a model accuracy of 100%, (note that this is a test environment, in the real world, you will nearly never get 100%), we would like to know more about the connection of our data and which input, or combination, corresponds to which class prediction. For this, we create artifical data, where we shuffle all out input features through. Then we test each input feature, which class the model predicts. For this, we use our unique feature values, and create input feature lists, where each single value is sent into the model, where all other values are set to zero. Also note, that we feed value-combinations into the model, it has not seen before. For this we we this code:
Which results in:
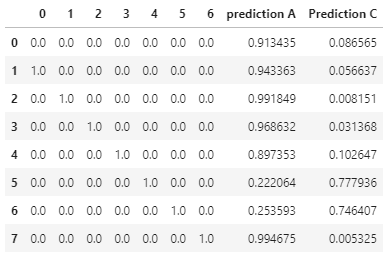
What does this DataFrame tell us now?
Having all input features set to zero (even zero itself, which the model never saw), we can see in the first line, that the model is rather biased to predict class-A. Also the features 1,2,3 and 6 are clear responsible for a class-A prediction. Features 4 and 5 are responsible for predictions of class-C.
Through a simple interation, we gained more insight about how our model works and what it is actually doing. However, this was just a start. We could also create combinations of our features, to see how each feature influences the occurence of another feature, which gets more important when using deep neural networks.
This blogpost is a more detailed answer to this stackoverflow question I wrote.
If you want to dig deeper into that topic, have a look at these publications:
- Methods for interpreting and understanding deep neural networks
- Sensitivity Analysis of Deep Neural Networks
Thank you for reading! Found it interesting, got a bug or questions? Want more information about this topic? Let me know and post a comment!